
香港出海基建不是买台服务器就完事。从服务器选型、网络合规、建站部署、站群架构、容灾高可用到数据主权,6 个环节有严格的先后依赖——跳步省下的钱,最后都变成重构的学费。
钱花了,服务器到位了,域名也解析了——然后呢?
上线那天晚上,大陆用户打不开页面,东南亚的回调丢了一片,CDN 缓存规则和动态接口打架,运维团队通宵排查才发现:网络层根本没做合规评估,数据出境这条线从头到尾没人管过。
这不是段子。
3 分钟先看结论: 香港出海基建是一套 6 个环节环环相扣的系统工程——服务器、网络、建站、站群、容灾、合规,任何一步跳过或顺序搞反,省下来的时间和预算,大概率在上线后以更大的代价爆雷。
花了大价钱,结果地基是歪的。做这行的人见过太多这种开局:团队把精力全砸在前端页面和功能开发上,服务器随便选了一家“看起来还行”的供应商,网络线路没验证,CDN 策略没分层,容灾方案停留在“到时候再说”。等到业务真跑起来,问题从底层一路往上炸。
说白了,出海基建不是一个单点采购问题。它是一条有严格先后依赖关系的链条。
这篇文章要做的事情只有一件:把这条链条上的 6 个环节拆开,告诉你每一步的核心坑点在哪,以及为什么跳步必翻车。具体线路质量和配置参数因供应商和时段差异较大,需结合实际环境验证——本文聚焦的是决策逻辑,不是参数推荐。
出海基建全景地图:6 个环节的先后依赖关系
在拆解每个环节之前,先把整条链路的依赖关系摆到桌面上。
下面这张图不是“功能清单”,而是一条有方向的决策链——前一步没做扎实,后一步的所有投入都建立在不稳的地基上。
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ ① 服务器选型 │ ───▶ │ ② 网络合规 │ ───▶ │ ③ 建站部署 │
│ (物理地基)│ │ (通道保障)│ │ (业务载体)│
└─────────────┘ └─────────────┘ └──────┬──────┘
│
┌─────────────────────┼─────────────────────┐
▼ │ ▼
┌─────────────┐ │ ┌─────────────┐
│ ④-A 站群矩阵 │ │ │ ④-B SaaS 部署│
│(多语言扩展)│ │ │ (平台化扩展)│
└──────┬──────┘ │ └──────┬──────┘
│ │ │
└─────────────────────┼─────────────────────┘
▼
┌─────────────┐
│ ⑤ 容灾 / 高可用│
│ (生存底线) │
└──────┬──────┘
│
▼
┌─────────────┐
│ ⑥ 监控与告警 │
│ (持续运营) │
└─────────────┘
基建架构需要持续迭代,本文提供的是方向性框架而非一次性方案。下面逐个拆解。
环节一:服务器选型——物理地基
所有后续环节的天花板,在这一步就定死了。
机房位置、硬件配置、带宽模型、远程管理能力——这四个维度里,大量团队只看了前两个,后两个等出事了才回头补课。带宽到底是独享还是共享?IPMI——也就是远程硬件管理接口,说白了就是不用跑去机房也能重启和监控服务器的工具——供应商到底给不给开放?这些问题不在签合同之前问清楚,后面全是被动。
环节二:网络与合规——通道保障
服务器到位了,但流量能不能顺畅地从用户端到达服务器、再从服务器回到用户端,这是另一个完全独立的问题。
BGP 线路,用一句话解释就是多线智能路由——多条运营商线路之间自动择优。听起来很美,但如果供应商的 BGP 接入质量本身有水分,“智能择优”就变成了“随机抽奖”。更深一层的坑在合规侧:跨境数据传输的红线,不同目标市场的网络监管政策,这些东西不是技术团队能单独搞定的。
环节三:建站部署——业务载体
地基和通道都就位之后,才轮到建站。
很多团队的问题恰恰出在这里:建站被当成了第一步。域名解析、SSL 证书、CDN 配置——也就是内容分发网络,把网站内容缓存到离用户最近的节点——WAF 策略,每一层都有自己的配置逻辑。WAF 这东西,听着很唬人,其实就是一道拦截恶意请求的安全门槛,但配错了规则,它拦的就不是攻击者,而是你自己的正常用户。
如果建站部署跳过了前两步直接开干,大概率会遇到一个经典场景:页面能打开,但接口超时;或者静态资源飞快,动态请求全卡在回源链路上。
环节四(分支 A):站群与多语言矩阵
单站跑通之后,很多团队的下一步是多语言站群。
这一步最大的认知误区,就是以为站群等于“把单站复制几份、翻译一下内容”。
不是这样的。每多一个语言版本,CDN 节点要不要加?WAF 规则要不要按区域分层?hreflang 标记——简单说就是告诉搜索引擎哪个语言版本该展示给哪个地区的用户——配没配对?这些问题一个都跳不过。站群的决策维度和单站完全不在一个量级上。
站群不是 Ctrl + C,每多一站都是一轮基建决策。
环节四(分支 B):SaaS 部署
另一条分支是 SaaS 化部署。
选型阶段看起来省心——供应商把底层都封装好了,开箱即用。但“开箱即用”背后藏着一个隐形大坑:你的数据跑在谁的基础设施上?云底座的区域选择、带宽模型、数据隔离策略,这些东西一旦在签约时没谈清楚,后面想迁移的成本远比重新搭建还高。
环节五:容灾与高可用——生存底线
前面四个环节解决的是“业务能跑起来”的问题。这个环节解决的是“业务挂了怎么办”。
很多团队对容灾的理解停留在“加个备份服务器”。
但容灾是一个分层问题。
服务器与网络:地基不稳,上面全白搭

回到最底层。
服务器选型和网络这两个环节之所以排在链条最前面,原因很朴素:它们出了问题,上面所有环节的投入全部归零。
真实情况是——线路质量虚标在这个市场里并不罕见。供应商宣传页上写的带宽数字和你实际跑起来的体验之间,经常存在一段不小的落差。CN2 GIA,也就是中国电信精品直连线路——号称大陆访问香港最稳的选择之一——但“精品”两个字背后的实际表现,取决于你拿到的是不是真正的 GIA 路由,而不是被混售的普通线路。
高防服务器这个品类,水分可能更深。“高防”两个字几乎成了营销标配,但防护能力到底是清洗中心级别的还是仅仅在路由层做了基础过滤,不实测根本看不出来。
线路质量和高防能力因供应商差异极大,本文仅提供排查方向,不构成供应商推荐。
还有一层容易被忽视的:SaaS 选型。如果你的业务有一部分跑在第三方 SaaS 平台上,那这个平台底层用的网络线路质量,同样会成为你整体基建的短板。
建站与站群:从单站到多语言矩阵的跨越
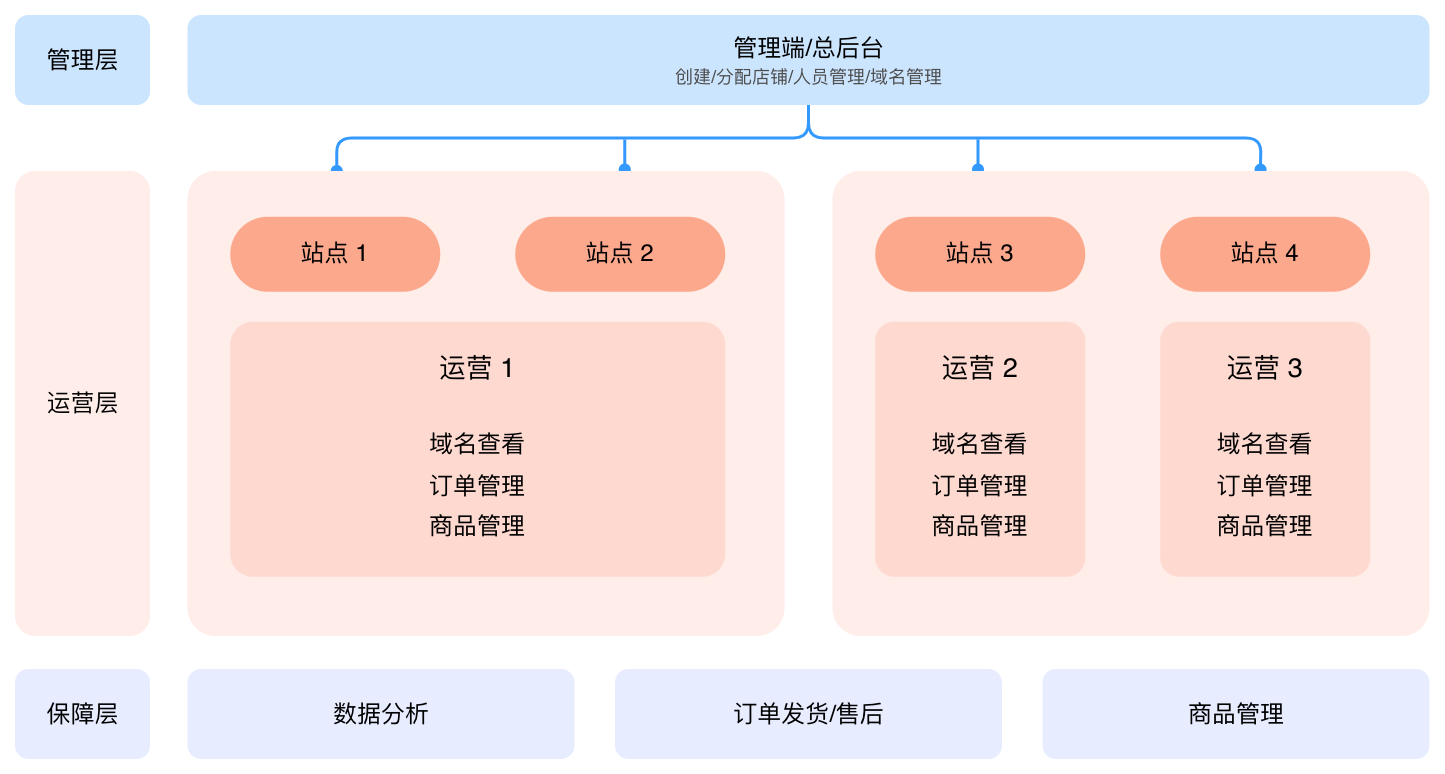
单站建站的技术复杂度,和多语言站群之间隔着一道鸿沟。
这道鸿沟不在代码层面——代码反而是最容易复制的部分。真正的差异在基建决策层面:CDN 回源策略要不要按区域拆分?(顺便说一句,CDN 回源就是缓存没命中的时候,节点回到你的源站重新取数据——这个动作如果跨了太远的物理距离,延迟会非常明显。)WAF 规则要不要按语言版本做差异化?域名结构是子域名还是子目录?
这些决策每一个都会影响后续的运维复杂度和扩展成本。
站群架构需要随业务规模持续调整,本文提供方向性框架。具体到你的业务场景,单站和站群之间的决策差异可以从几个维度去对比:
| 决策维度 | 单站 | 多语言站群 |
|---|---|---|
| CDN 策略 | 单一回源 | 按区域分层回源 |
| WAF 规则 | 统一规则集 | 按语言 / 地区差异化 |
| 域名结构 | 单域名 | 子域名 or 子目录,影响 SEO 权重分配 |
| 内容同步 | 不涉及 | 多版本内容一致性管理 |
| 监控粒度 | 单节点 | 多节点分布式监控 |
站群的本质不是复制,是把基建决策重新做一遍。
容灾与高可用:不是等出事才想起来的事
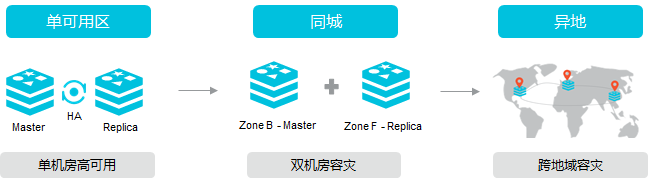
大量血泪案例证明,容灾方案的价值体现在你用不到它的时候。一旦真用到了,它的价值取决于你提前规划了多少。
先做一个排查:你现在的架构里,主节点挂了之后,流量会去哪?
如果答案是“不知道”或者“应该会自动切吧”,那问题已经很明确了。故障切换——也就是主备自动切换,主节点故障时备用节点自动接管流量——这个动作听起来简单,但背后需要回答的问题一点都不简单:切换的触发条件是什么?切换过程中数据怎么处理?切换之后 DNS 缓存多久才能刷新?
然后是两个绕不开的概念。
RTO,恢复时间目标——打个比方,就像你给自己定的“最晚几点到公司”的底线,只不过这里的“到公司”是“把服务恢复正常”。RPO,恢复点目标——换个说法就是你能接受丢多少数据,是最近一分钟的还是最近一小时的(这个问题的答案直接决定了你的备份策略和成本)。
这两个目标不是拍脑袋定的。它们需要根据业务等级分层设定——核心交易链路和静态内容页面,显然不该用同一套标准。
盘面上的硬道理是——只靠一个节点,迟早出事。多区域部署不是大厂的专利,而是任何对可用性有要求的业务都需要认真考虑的架构选择。
容灾策略需结合业务 SLA 要求持续优化,本文仅提供规划方向。如果你的业务涉及高并发场景,容灾和多区域部署的复杂度还会再上一个量级。
基建最贵的不是硬件,是重来
商业铁律就在于:基建决策的真正成本,从来不是硬件账单上那个数字。
行业里有一个根深蒂固的共识——“出海基建嘛,就是买服务器、开 CDN、配个域名,技术活儿而已。”
这个共识害了太多团队。
我们交过的学费里,印象最深的一课是这样的:项目初期为了赶上线节点,基建环节能省则省,架构设计留了一堆“先这样,以后再优化”的口子。结果业务跑起来之后,那些被跳过的环节一个接一个地爆雷——网络层要重新选线路,CDN 策略要推翻重配,容灾方案要从零补建。每一次重构,不光是技术成本,还有业务停摆的时间成本、团队士气的消耗、以及跟供应商重新谈判的沟通成本。
做基建这件事,账要反过来算:跳步省下的预算,在重构的时候大概率 3 倍还回来。这不是精确计算,而是经验性判断——但方向不会错。
省下的基建预算,最终都变成重构学费。
合规与数据主权:出海基建的隐形地雷
如果前面几个环节是“看得见的坑”,合规与数据主权就是那颗“踩上去才知道的地雷”。
我们做过的对接项目里,合规问题往往不是技术团队最先发现的——而是业务已经跑了一段时间之后,突然收到某个市场的监管通知,才意识到数据存储和传输链路从一开始就没做对。
东南亚市场尤其复杂。
PDPA——说直白点就是各国各自搞的一套个人数据保护法——在不同国家的执行力度和具体要求差异很大。有的国家要求数据本地化,意思是用户数据必须物理存储在本国境内,不能出境。有的国家对跨境数据传输——也就是数据从一个国家流动到另一个国家——有专门的审批流程或合规框架。
盘面上的硬道理是——你的网络架构选型,从第一步就决定了你在合规层面的活动空间。如果服务器全部部署在香港,但目标市场要求数据本地化,那你后面要么补建当地节点,要么面对合规风险。
各国数据保护法规差异极大且持续更新,本文仅提供方向性认知,具体合规方案应咨询当地法律顾问。
架构决定合规空间,第一步就不能选错方向。
常见问题
Q1:香港服务器和东南亚本地服务器怎么选?
不存在一个通用答案。
很多团队的第一反应是“目标用户在哪就把服务器放在哪”,这个逻辑听起来合理,但忽略了一个关键变量:你的业务架构是集中式还是分布式。如果是集中式架构,香港作为亚太网络枢纽的优势在于多方向的线路覆盖能力;如果是分布式架构,核心节点放香港、边缘节点放目标市场本地,可能是更务实的方案。
反过来说,如果不考虑架构直接按“哪便宜选哪”的逻辑决策,大概率会在后续扩展时遇到网络链路不通或合规踩线的问题。以上为方向性建议,具体方案需结合业务实际评估。
Q2:出海基建一定要用独享带宽吗,共享带宽行不行?
取决于你的业务流量模型。
共享带宽在流量平稳、并发不高的场景下确实能省成本。但如果你的业务存在明显的流量波峰——比如促销活动、特定时段的集中访问——共享带宽在高峰期的实际可用带宽可能远低于标称值。这不是供应商的问题,而是共享模型的底层逻辑决定的。
常见的误判是“先用共享带宽跑着,不够了再升级”。问题在于,从共享切换到独享往往不是简单的“升级套餐”,可能涉及 IP 变更、DNS 重新解析、甚至机房迁移。以上为方向性建议,具体方案需结合业务实际评估。
Q3:基建上线后监控告警怎么做,有没有最小化方案?
监控不是上线之后才想的事,但确实可以分阶段建设。
最小化方案的核心是抓住几个关键指标:服务可用性(页面能不能打开)、接口响应时间(核心业务接口的延迟是否在可接受范围内)、证书到期预警、以及带宽使用率。这几项用开源工具就能覆盖基础需求。
反例是“上线之后再慢慢搭监控”——等到某天凌晨服务挂了、没有任何告警、第二天用户投诉才发现的时候,补救成本远高于提前部署一套基础监控。以上为方向性建议,具体方案需结合业务实际评估。
Q4:基建预算有限,哪些环节可以分阶段做,哪些必须一步到位?
服务器选型和网络合规这两个环节,必须一步到位。
原因很简单:它们是地基。地基歪了,上面的建筑不管多漂亮,迟早要拆掉重来。
可以分阶段的环节包括:站群扩展(先跑通单站再考虑多语言矩阵)、监控体系(先覆盖核心指标再逐步完善)、以及容灾方案的精细度(先做到基础的主备切换,再逐步提升 RTO / RPO 目标)。
反例是“所有环节都分阶段慢慢来”——如果地基环节也被拖到“下一期再补”,那大概率不会有下一期,因为业务会先在地基问题上翻车。以上为方向性建议,具体方案需结合业务实际评估。
出海基建自检:上线前过一遍这张清单
写到这里,该拆的环节都拆完了,该指的坑也都指到了。
但看完和做到之间,还差一步。
WG 长期服务出海团队的基建落地,从智能包网的整套平台搭建、系统配置、游戏整合、支付接入,到多语言多端适配——我们见过太多团队在上线前跳过某个环节,上线后返工的成本远高于前期规划投入。基建是一个持续迭代的过程,不是一锤子买卖。
如果你现在正在规划香港出海基建,建议上线前拿这 4 要素做一次自检:
时间锚点——上线前,每个环节的验证节点是否已经排进了项目计划?
失败动作——有没有哪个环节被标注了“先跳过、以后再补”?
后果细节——那些被跳过的环节,一旦出问题,影响面有多大?是局部降级还是全局瘫痪?
决策依据——每个环节的供应商选择和架构方案,是基于实测验证还是基于销售话术?
带着这张清单,找我们过一遍思路——不是替你接管开发,而是结合你的业务做一次方向性拆解,把那些容易被跳过的环节提前摊到桌面上。