
Web3 出海团队的核心风险往往不是外部攻击,而是内部治理失控。本文提供一套覆盖权限隔离、资金多签、代码数据治理与应急预案的 4 层企业级 IT 治理框架,帮助分布式团队建立真正的抗单点故障能力。
Web3 出海企业的最大风险往往不是外部攻击,而是内部治理的单点崩塌。本文提供一套覆盖人员权限、资金密钥、代码数据、应急连续性的 4 层 IT 治理框架,帮助分布式团队构建真正抗单点故障的企业级架构。
那个人失联的那天,服务器就没人能登了。
一支分布在三个时区的 Web3 出海团队,核心技术合伙人掌握着所有生产服务器的 root 权限、代码仓库的唯一管理员账号,以及公司数字资产托管账户的关键签名权。某天凌晨,这个人的所有通讯渠道同时断线。
剩下的人打开电脑才发现:服务器登不上,代码改不了,资金取不出来。
在缺乏冗余治理架构的情况下,这种事故大概率会导致业务全面中断。而这不是极端假设——这是行业里每年都会反复出现的真实事故模式。
3 分钟先看结论: Web3 出海团队最大的风险不是外部攻击,是内部治理崩塌。权限集中、密钥单点、预案空转——任何一项短板都可能让业务一夜归零。本文拆解 4 层防御体系的完整框架。
安全的本质不是加密,是“去中心化治理”

这个行业有一个极其讽刺的现象。
大多数 Web3 团队天天把“去中心化”挂在嘴边,但自己公司的治理架构却是最中心化的——所有服务器权限集中在一个人手里,代码仓库只有一个管理员,资金签名权绑定在单一设备上。
天天喊去中心化的团队,自己的治理却最中心化。
商业铁律就在于:如果团队的权限架构存在单点依赖,那么安全的本质问题就不在加密强度,而在治理结构。
把密码从 8 位改成 32 位,不会解决“这个人消失了整个系统就瘫了”的问题。单点故障——(这里要插一句解释:所谓单点故障,就是整条链路上有一个环节挂掉,整个系统跟着挂)——才是分布式团队最应该优先消灭的敌人。
这就是为什么需要一套“分布式治理架构”:权限分散到多个独立节点,密钥用分布式管理协议拆分,代码做异地多备份,资金走多签审批。让任何单一节点——无论是人、设备还是账号——的消失,都不会导致系统崩溃。
这套架构不复杂,但需要从第一天就设计进去。补课的代价远高于预防。
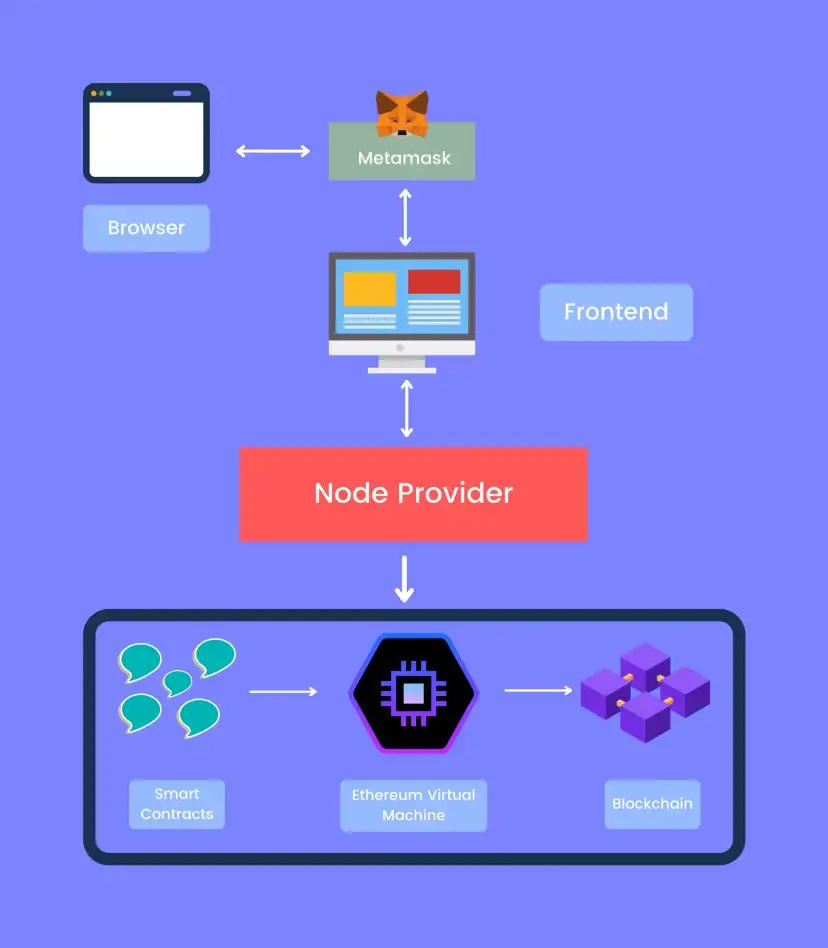
企业 IT 治理全景图:4 层防御体系
在展开每一层之前,先看一张总图。
这 4 层构成了一套完整的企业级 IT 治理框架,每一层解决一个核心问题。如果其中任何一层存在明显短板,整体架构的韧性就会大打折扣——锁了前门却开着后门,防御体系形同虚设。
┌─────────────────────────────────────────────┐
│ 第 1 层:人员与权限(谁能碰什么) │
│ → 权限隔离 · 职责分离 · 设备管控 │
├─────────────────────────────────────────────┤
│ 第 2 层:资金与密钥(钱怎么管) │
│ → 多签门限 · MPC-TSS · 签名权分散 │
├─────────────────────────────────────────────┤
│ 第 3 层:代码与数据(知识怎么存) │
│ → 异地备份 · 脱敏处理 · 合规生命周期管理 │
├─────────────────────────────────────────────┤
│ 第 4 层:应急与连续性(出事怎么办) │
│ → BCP 预案 · 72 小时手册 · 定期演练 │
└─────────────────────────────────────────────┘
以下逐层拆解核心风险和解法方向。每一层点到为止,深度拆解另有专文。
第 1 层:人员与权限——谁能碰什么
分布式团队的第一道防线,不是防火墙,是权限边界。
核心风险只有一句话:如果一个人同时拥有服务器 root 权限、代码仓库管理权和资金签名权,那么这个人就是整个业务的单点故障。(这里要插一句解释:所谓职责分离原则(Segregation of Duties),就是“碰钱的人不碰代码,碰代码的人不碰服务器”——用制度把权力拆开,让任何单一角色都无法独立完成高风险操作。)
解法方向很清晰:
- 权限最小化: 每个角色只拥有完成本职工作所需的最低权限,多一项都不给。
- 敏感操作双人确认: 涉及资金、数据删除、权限变更的操作,必须由两个独立角色共同授权。
- 设备隔离: 工作设备与个人设备严格分开,远程接入必须走受控通道。
这一层的展开逻辑——从设备管控到权限吊销的实操手册——值得技术负责人单独花时间看一遍。
第 2 层:资金与密钥——钱怎么管
权限管好了,下一个问题是钱。
Web3 企业的资金管理和传统企业有一个本质区别:数字资产的转移是不可逆的。传统银行转账出了问题还能冻结、追回;链上资产一旦被转走,技术层面几乎没有回头路。
这意味着资金管控的容错空间极小。
核心风险:如果签名权集中在单人手里,那么这个人——无论是主动还是被动——都有能力让公司资金在几分钟内清零。
解法方向:
- 2/3 多签门限: 任何一笔资金操作至少需要三分之二的授权签名人同时确认,单人无法独立完成转账。
- MPC-TSS 密钥分布式管理: MPC-TSS 这玩意儿,本质上就是把一把钥匙拆成几片,分别保管在不同的人手里、不同的设备上、不同的地理位置——任何单片都无法独立使用,必须凑齐门限数量才能签名。
这一层的深度拆解——传统多签和 MPC-TSS 的真实差异、内部资金风险的防控逻辑——需要单独展开。
第 3 层:代码与数据——知识怎么存
先问一个具体问题:你的代码仓库,现在有几个人有管理员权限?如果答案是“一个”,那这一层的风险已经暴露了。
真实情况是——很多团队在代码和数据管理上的短板,不是“没做备份”,而是“备份了但没人知道在哪”“备份了但恢复流程没跑通过”。
核心风险有两个维度:
丢失维度: 代码仓库没有异地冗余备份,一旦主仓库不可访问(无论是人为还是平台封禁),业务代码就断了。
泄露维度: 用户数据在存储和传输过程中没有做脱敏处理,一旦发生数据泄露,合规后果极其严重。
解法方向:
- 代码仓库异地多备份: 至少在两个独立平台保持同步镜像,管理员权限分散到多人。
- 数据写入前先做哈希脱敏: 敏感字段在落库之前就完成不可逆脱敏,即使数据库被拖,泄露的也是脱敏后的数据。
- 合规数据生命周期管理: 数据的存储、归档、删除都有明确的时间节点和操作规范。删除时用多次覆盖擦除——这个词说人话就是“不是把文件拖进回收站,而是在磁盘上反复写入随机数据,让原始信息彻底不可恢复”。
这一层的技术细节——从脱敏算法选型到合规删除的操作规范——另有专文拆解。
第 4 层:应急与连续性——出事怎么办
前三层是“防”,这一层是“救”。
再完善的防御体系也无法保证永远不出事。真正区分业余团队和专业团队的,是出事之后的响应速度和恢复能力。
核心风险:大多数团队的应急预案停留在“写了一份文档放在共享盘里”的阶段——从来没有演练过,真正出事时才发现流程跑不通、联系人找不到、备用方案根本不存在。
解法方向:
- 建立符合 ISO 22301 标准的业务连续性预案(BCP): BCP,翻成大白话就是“出事了按什么顺序做什么事”的标准化剧本。
- 定期演练: 建议每季度做一次业务连续性演练,模拟核心节点失效场景,验证备用方案是否真正可用。
- 跨区域分布式存储: 关键业务数据在至少两个独立地理节点保持实时同步,确保单一区域不可用时业务可以快速切换。
这一层的基建细节——跨区域存储怎么搭、分布式集群怎么部署——值得基建负责人深入了解。
关键人失联的 72 小时行动手册
4 层防御体系是“治本”,但现实中总有“治标”的紧迫时刻。
在行业实践中协助过的应急演练里,最常见的一个发现是:团队对“关键人突然无法履职”这件事的准备程度,远低于自己的预期。大多数团队在模拟演练的前几个小时就陷入了混乱——不是能力不够,是没有预设过行动框架。
以下是一份建议性的 72 小时行动框架。具体时间窗口需根据团队实际情况调整,但三个阶段的优先级排序具有普遍参考价值。
第一阶段:0-4 小时——确认与隔离
核心动作: 确认失联性质,启动备用通讯渠道。
- 区分“主动缺位”(离职、主动断联)与“被动缺位”(因不可抗力无法履职)。两种情况的后续处理路径完全不同。
- 启动预设的备用通讯渠道(备用即时通讯群组、紧急联络人电话树)。
- 冻结该人员名下的高危权限入口(生产服务器、资金签名设备),防止权限在失控状态下被利用。
⚠️ 此阶段的建议适用于分布式团队的标准场景。单一办公地点的团队,初步确认流程可能更快,但权限隔离的优先级不变。
第二阶段:4-24 小时——权限冻结与备用启用
核心动作: 全面冻结该人员的所有系统权限,启用备用管理员。
- 逐一排查该人员名下的所有权限清单:服务器 root、代码仓库管理员、资金签名权、第三方 SaaS 平台管理员。
- 按权限清单逐项冻结或转移至备用管理员。
- 启用预设的备用管理员账号(如果没有预设——这本身就是治理架构的重大漏洞)。
⚠️ 权限冻结操作建议由至少两名授权管理员共同执行,避免单人操作带来的误操作风险或审计争议。
第三阶段:24-72 小时——影响评估与恢复启动
核心动作: 评估业务影响范围,启动数据和资金的应急恢复流程。
- 盘点该人员经手的所有业务模块,评估哪些模块因其缺位而面临中断风险。
- 启动资金应急恢复流程:如果该人员持有多签密钥的一片,评估剩余签名人是否满足门限要求。
- 启动数据恢复流程:确认代码仓库的异地备份是否可用,关键业务数据是否可从备用节点恢复。
⚠️ 72 小时手册是应急响应框架,不是长期方案。长期方案应建立常态化的权限轮换与审计机制,确保任何单一节点的缺位都不会触发系统性风险。
应急预案不是写给出事那天看的,是写给今天就必须演练的。
补充:核心成员离职交接 SOP
72 小时手册应对的是“突发缺位”,但更常见的场景是“计划内离职”。如果离职交接没有标准化流程,同样会留下治理漏洞。
一份基本的离职交接 SOP 应覆盖以下三个维度:
- 知识文档归档: 该成员经手的所有技术文档、架构决策记录、运维手册,必须在离职前完成归档和交接确认。
- 权限回收清单: 逐项回收所有系统权限(服务器、代码仓库、SaaS 平台、资金签名设备),确认回收完成后由第二人复核。
- 客户关系交接: 该成员对接的外部合作方、供应商、服务商,必须在离职前完成正式交接通知。
应急预案的前提,是企业的底层架构本身就具备抗风险能力——包括离岸实体的合规配置。这件事的选型逻辑另有专文拆解。
治理架构的韧性,才是出海的终极竞争力
在行业观察中,一个反复被验证的判断是:Web3 出海的竞争,表面上拼的是产品和流量,底层拼的是治理架构的韧性。
那些能穿越周期活下来的团队,往往不是跑得最快的,而是在遭遇冲击后能最快恢复运转的。
能活到最后的团队,不是跑得最快的,是摔倒后站得最快的。
回到本文开头那个场景:一个人失联,整个业务瘫痪。这件事之所以反复发生,不是因为团队不够聪明,而是因为治理架构从第一天起就没有被认真设计过。
4 层防御体系——人员权限、资金密钥、代码数据、应急连续性——不是一套理论框架,而是一张可以逐项落地的检查清单。
如果你的团队正在搭建或重组出海架构,或者意识到当前的权限和资金管理存在单点风险,可以预约一次轻量级的架构健康度评估。不替你接管开发,更多是帮你过一遍这 4 层防御体系的现状,提供方向性建议——思路你拿走自己用就行。
常见问题
Q1:团队只有几个人,有必要搞这么复杂的权限隔离吗?
恰恰相反——团队越小,权限隔离越重要。大团队出了事还有冗余人手顶上,小团队一个人出问题就是全线停摆。行业实践中有一个典型事故模式:某个早期团队只有四五个人,创始人兼任技术负责人,所有权限绑在他一个人身上。后来这个人因个人原因突然无法履职,剩下的人连生产服务器都登不上,业务停了好几天才勉强恢复。权限隔离不是大公司的专利,是所有团队的生存底线。
Q2:MPC-TSS 听起来很复杂,传统多签钱包够用吗?
传统多签在很多场景下确实够用,但有一个结构性短板需要提前想清楚:如果某个签名人失联,剩余签名人能否独立完成操作?传统多签的签名人身份是公开绑定的,一旦某个签名人出了问题,替换流程往往很复杂。MPC-TSS 的核心优势在于密钥分片可以动态重组,不依赖固定的签名人身份。具体选哪种,取决于团队的资金规模和人员稳定性——但无论选哪种,“单人掌握全部签名权”都是必须消灭的结构性风险。
Q3:应急预案写了但从来没演练过,有什么实际风险?
风险极大。这就像写字楼贴了疏散路线图但从来不做消防演练——真正着火的时候,大概率发现安全门打不开、疏散通道堆满了杂物、员工根本不知道集合点在哪。应急预案的价值不在“写了”,在“跑通了”。建议每季度做一次模拟演练:随机指定一个核心成员“失联”,看剩下的人能不能在预设时间内完成权限切换和业务恢复。第一次演练的结果往往会让团队非常意外。
Q4:远程团队成员分布在不同国家,试用期的权限管控怎么处理?
核心原则是“权限随信任梯度递增”。试用期内只开放完成工作所需的最低权限,严禁一上来就给全量代码仓库访问权。行业里有过这样的事故:某团队给试用期员工开放了完整的代码仓库权限,这个人没过试用期就离职了,但权限回收滞后了好几天——期间这个人理论上仍然可以访问全部源代码。正确的做法是:试用期内权限分级发放,转正后逐步升级,离职当天权限即时回收并由第二人复核。
Q5:72 小时行动手册是不是太理想化了?真实场景下能执行吗?
能,但前提是平时就做过演练。如果团队从来没有模拟过“关键人缺位”的场景,那么真正出事时,前几个小时大概率会在混乱中浪费掉——不是在执行预案,而是在争论“现在该怎么办”。72 小时手册的价值不在于时间切分精确到小时,而在于它预设了优先级排序:先隔离风险、再冻结权限、最后评估恢复。有这个框架和没有这个框架,团队在危机中的响应效率差距是质变级别的。