
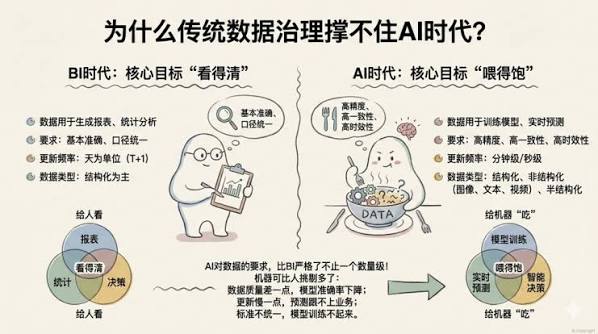
AI 数据治理怎么做才不踩合规线?出海团队喂数据给 AI,最常见的误区是"脱敏越狠越安全"——其实脱敏太狠 AI 变傻、太松合规爆雷,这是个三角权衡。
先抛个反共识结论
AI 数据治理不是 AI 的前置工程,是出海合规的延伸战场。很多团队把它当成“上线前清洗一下数据”的技术活,结果数据跑进模型才发现踩了跨境合规的线。喂数据给 AI,难的从来不是技术,是你懂不懂哪条线碰不得。本文不构成法律意见,各市场法规差异极大,以目标市场现行法规为准。
喂数据这件事,多数团队一开始就想错了
都说数据脱敏越狠越安全。
错。
也有人说,AI 数据治理嘛,不就是上线前把数据洗一洗、把名字打个码?
也错。
这两个误解,几乎是出海团队在 AI 数据治理上栽跟头的标准姿势。前一个让你的 AI 越喂越笨,后一个让你在合规上埋雷而不自知。
把这件事的本质说穿:你喂给 AI 的每一条用户数据,背后都连着两根线——一根是 AI 的可用性,一根是合规的红线。这两根线,常常往相反的方向拉扯。只盯着一根,另一根迟早崩给你看。
AI 数据治理真正要解决的,就是怎么在这两根线之间走稳。这篇不讲虚的,直接拆开讲:数据怎么分级、脱敏怎么把握分寸、跨境的红线在哪。
喂之前先分级:哪些能喂、哪些碰都别碰

在谈脱敏之前,有个动作不能跳——AI 数据分类分级。
道理很朴素:不是所有数据都一个待遇。把数据按敏感程度分层,是后面一切治理动作的地基。
大致可以分成这么几层:完全不敏感的(比如脱敏后的行为统计),中度敏感的(比如用户偏好、设备信息),以及高度敏感的(比如身份证件、支付信息、生物特征这类)。层级不同,能不能喂给 AI、要怎么处理,规矩完全不一样。
最高敏感的那一层,原则上碰都别直接碰——尤其在你还没想清楚“该不该上 AI、这个场景值不值得”之前,更别急着把敏感数据往模型里倒。
该不该上 AI 先想清楚
分级做完,才轮到那个最容易出错的环节:脱敏。
数据脱敏 × AI 可用性:脱敏不是越狠越好
都说脱敏越彻底越安全,把数据打码打到亲妈都不认识就万事大吉。
这个想法,经不起推敲。
先从机理上说清楚,AI 数据脱敏为什么会让 AI“变笨”。AI 是从数据的细节和关联里学规律的。脱敏——通俗说就是把能认出具体某个人的信息抹掉或替换掉——本质是在删信息。你抹得越狠,数据里能让 AI 学习的“养分”也被抹得越多。抹到极致,数据是绝对安全了,可也变成了一堆没营养的噪声,AI 学不出任何有用的东西。
这里有几种常见的脱敏路子,顺带祛个魅。
“k-匿名”,说白了就是让每条记录至少和另外 k-1 条长得一样,单看一条认不出是谁。
“差分隐私”,可以打个比方:在数据里掺一点精心计算过的“噪声”,让你看不清单个个体,但整体规律还在。
这些方法各有各的代价,掺的“保护”越重,留下的“可用性”往往越少。
所以真相是一个三角权衡:脱敏强度、AI 可用性、合规风险,三者互相拉扯,按下一个就翘起另一个。
【脱敏权衡三角 · 定性】
脱敏强度 高
▲
│
合规风险 ↓ │ AI 可用性 ↓
(更安全) │ (更笨)
│
─────────────┼─────────────
│
合规风险 ↑ │ AI 可用性 ↑
(更危险) │ (更聪明)
│
脱敏强度 低
⚠️ 三者拉扯:没有“全都要”,只有“找平衡”
(三角为定性示意,脱敏与可用性的具体关系因数据与模型而异,须结合自身验证。)
脱敏太狠 AI 变傻,脱敏太松合规爆雷。
那怎么办?答案不是“找一个完美脱敏值”,是分级脱敏。
分级脱敏策略清单(按数据层级配脱敏强度)
1. 高敏感数据(身份 / 支付 / 生物特征)→ 最强脱敏或干脆不喂。 后果:宁可 AI 笨一点,也别拿这类数据冒险。
2. 中敏感数据(偏好 / 设备)→ 适度脱敏 + 评估可用性。 后果:在可用和安全之间找平衡点,别一刀切。
3. 低敏感数据(脱敏后统计)→ 轻度处理,保留可用性。 后果:让 AI 有足够养分学习。
4. 任何分级,都先问“这个场景真需要这么细的数据吗”。 后果:不需要的细节,本就不该喂。
顺带说一句,脱敏不是免费的——它本身也是数据治理成本里实打实的一笔。这一环的成本怎么权衡,是另一个话题。
这一环成本怎么算
脱敏的分寸把握住了,还有一条更硬的线在前面——跨境。
跨境数据流动合规:三类红线,碰不得
⚠️ 本节不构成法律 / 合规专业意见。各市场数据法规差异极大,请以目标市场现行法规及专业意见为准。
脱敏是技术活,还能自己拿捏。跨境,是法律活,拿捏不得。
出海团队喂数据给 AI,常常一不留神就触发了“数据跨境”——打个旁白:很多 AI 服务的服务器、算力在境外,你的数据一喂进去,可能就跨了境,而你自己未必意识到。跨境数据流动 AI 这件事,红线比你想的密。
定性地说,至少有三类红线要心里有数。
GDPR 方向。 这是欧盟的数据保护框架,对个人数据的处理、跨境传输有严格要求。涉及欧盟用户数据,得格外当心。具体要求以欧盟现行法规为准。
PDPA 方向。 不少亚太市场(如新加坡等)有各自的个人数据保护法,要求各不相同。做哪个市场,就得看哪个市场的规矩。具体以当地现行法规为准。
数据出境方向。 一些国家 / 地区对数据离境本身有专门约束,什么数据能出、怎么出、要不要审批,都有讲究。具体以目标市场现行规定为准。
这里要把一件事单独拎出来辨清楚。
都说“做好脱敏就能随便跨境了吧”?不一定。
逐条看:脱敏降低的是数据被识别的风险,但“数据能不能出境”是另一个维度的问题——有些规定管的是数据流向本身,不只看你脱没脱敏。把“脱敏”当成“跨境通行证”,是个危险的想当然。
所以立论很清楚:脱敏和跨境合规是两回事,做了前者不等于过了后者。
【三类跨境红线 · 定性对照矩阵】
| 红线 | 适用地区 | 核心关注 | AI 场景影响 |
|---|---|---|---|
| GDPR 方向 | 欧盟相关 | 个人数据处理与跨境传输 | 喂欧盟用户数据需谨慎 |
| PDPA 方向 | 部分亚太市场 | 个人数据保护(各地不同) | 按目标市场分别评估 |
| 数据出境 | 部分国家 / 地区 | 数据离境本身的约束 | 境外算力 / 服务需排查 |
(矩阵为定性框架,不含任何数字,各地区要求差异极大且会更新;具体以目标市场现行法规为准,建议由专业人士独立评估。)
要说清楚:这一节只讲红线在哪,不讲、也不会讲任何“怎么绕过”的东西。合规这条线,正确的姿态是认真过,不是想办法躲。这也只是 AI 落地诸多坑里的一个——
AI 落地还有哪些坑
⚠️ 再次提醒:本节为定性框架,不替代专业合规意见。跨境数据合规各地区差异极大且持续更新,具体请以你目标市场的现行法规为准,并由专业人士独立评估。
数据治理是合规的延伸,不是 AI 的前菜
行业里聊 AI 数据治理,默认把它放在“AI 工程”的篮子里——好像它只是模型上线前的一道技术工序,洗洗数据、打打码,完事。
这个定位,从根上就摆错了。
做这行久了会看清一件事:那些在数据治理上栽得最惨的团队,往往不是技术不行,是把它当成了纯技术问题。某个出海游戏团队就踩过这种亏——上线前一门心思优化模型效果,数据脱敏、跨境这些“合规的事”全推给“以后再说”。上线第几天就发现,数据早就以不合规的方式喂进了模型,想补救,得把数据链路整个返工。
问题出在哪?他们把数据治理当成了 AI 的前菜,而它本该是合规的正餐。
真实情况是——数据怎么收、怎么分级、怎么脱敏、能不能跨境,这些问题的根都扎在出海合规体系里,不在 AI 技术里。AI 只是让这些老问题,以新的、更密集的方式爆发出来。
数据治理是合规的延伸,不是 AI 的前菜。
所以正确的顺序是:先有合规架构,再谈喂数据给 AI。把合规当地基,AI 才盖得稳;把合规当装修,迟早返工。
数据合规这关
FAQ
Q1:用户数据能不能直接喂给 AI?
很多人以为数据收上来就能直接喂,其实不能。用户数据能不能喂给 AI,取决于数据敏感等级、用户授权范围,以及你要喂去的场景。高敏感数据原则上别直接喂;其余数据也要先分级、按规处理。直接把原始用户数据倒进模型,是最常见也最危险的踩线动作。
Q2:脱敏后 AI 还准不准?
不少人担心脱敏会把 AI 搞废,其实关键在“分级”而非“一刀切”。脱敏太狠确实会削弱 AI 可用性,但通过分级脱敏——高敏感重保护、低敏感轻处理——多数场景能在合规和可用之间找到平衡。准不准,取决于你脱敏的分寸,不是脱敏这件事本身。
Q3:数据留存多久才合规?
没有一个放之四海皆准的天数。GDPR 下 AI 怎么用数据、数据该留多久,不同市场、不同数据类型要求各异,核心原则通常是“按必要性留存、用完即清”。这里不给任何具体天数,因为写死的数字只会误导你。
Q4:向量库存的数据,算不算个人信息?
这是个容易被忽略的点。AI 训练数据要不要脱敏,连带着向量库也得考虑——把用户数据向量化存进向量库,如果还能关联回具体个人,很可能仍被视为个人信息,同样受合规约束。别以为“转成向量”就脱离了监管。具体认定以目标市场法规为准。
写在最后:先把数据这关过了,再谈喂 AI
绕回开头那个被想错的问题——AI 数据治理到底是什么?
到这儿答案清楚了:它不是 AI 上线前的一道技术工序,是出海合规体系往 AI 场景的延伸。喂数据给 AI,真正的功夫在喂之前——分好级、把握住脱敏的分寸、看清跨境的红线。这几步走稳了,AI 才跑得安心。
做这行踩过的亏里,有一类最冤:模型调得再好,数据这关没过,上线即返工。准备上 AI、却卡在数据这关的团队,太多了。治理没做对,AI 跑起来才发现合规爆雷,那时候返工的成本,比一开始就做对贵得多。
如果你正卡在这一步,需要一次 AI 数据合规方案 的梳理,或者 出海数据治理服务 的拆解——可以把你的数据现状拿来,做一次“合规 × AI 可用性”的拆解,看看哪些数据能喂、哪些得先处理、哪条跨境线还悬着。我们不替您接管数据治理,也不做任何“包过 GDPR、保证合规、绝对安全”这类承诺(各市场法规差异极大,这种话本身就不成立);能做的,是以老炮分享的姿态,陪您把数据这关的思路过一遍。
数据治理这关,早过一天,AI 就少返一次工。先把合规地基打好,再谈喂数据。